
RocketMQçڑ„ه¹¶هڈ‘读ه†™èƒ½هٹ›و‰›ن½ڈن؛†2016ه¹´هڈŒهچپن¸€ï¼Œو¯ڈ秒17.5ن¸‡ç¬”订هچ•çڑ„هˆ›ه»؛(هچ•ç¬”订هچ•è،چç”ںه‡؛Nو،و¶ˆوپ¯ï¼Œه®é™…tpsوک¯17.5*n ن¸‡ï¼‰ï¼Œن¸‹é¢ه¯¹ه…¶é«که¹¶هڈ‘读ه†™هژںçگ†è؟›è،Œوژ¢è®¨م€‚ن¸»è¦پن½“çژ°هœ¨ن¸¤و–¹é¢ï¼ڑه®¢وˆ·ç«¯و”¶هڈ‘و¶ˆوپ¯ï¼Œوœچهٹ،ه™¨وژ¥و”¶و¶ˆوپ¯ه¹¶وŒپن¹…هŒ–(é‡چ点)م€‚
ه®¢وˆ·ç«¯(RocketMQ-client)
1,ه®¢وˆ·ç«¯هڈ‘é€پو¶ˆوپ¯وœ‰è´ںè½½ه‡è،،,ه®¢وˆ·ç«¯ه†…هکن¸ن؟هکç€ه½“ه‰چو‰€وœ‰çڑ„وœچهٹ،ه™¨هˆ—è،¨ï¼Œو¯ڈو¬،هڈ‘é€پ都هˆ‡وچ¢ن¸€هڈ°وœچهٹ،ه™¨هڈ‘é€پو¶ˆوپ¯ï¼Œن½؟ه¾—و¯ڈهڈ°وœچهٹ،ه™¨وژ¥و”¶çڑ„و¶ˆوپ¯é‡ڈه°½é‡ڈه‡è،،,éپ؟ه…چçƒç‚¹é—®é¢کم€‚
2,هڈ‘é€پن»£ç پن¸؛ç؛؟程ه®‰ه…¨ï¼Œه½“Producerه®ن¾‹ه°±ç»ھن¹‹هگژ,ه®Œه…¨هڈ¯ن»¥و»ه¾ھçژ¯هڈ‘é€پو¶ˆوپ¯م€‚ن¸€èˆ¬ن¸ڑهٹ،و–¹éƒ½ن¼ڑوœ‰Nن¸ھو•°وچ®و؛گه®ن¾‹ï¼Œو‰€ن»¥ن»ژو•°وچ®و؛گو–¹é¢ه°±ن؟è¯پé«که¹¶هڈ‘ه†™èƒ½هٹ›م€‚
3,و¶ˆè´¹è€…端è´ںè½½ه‡è،،集群و¶ˆè´¹و¨،ه¼ڈن¸‹ï¼ŒهگŒن¸€ن¸ھIDçڑ„و‰€وœ‰و¶ˆè´¹è€…ه®ن¾‹ه¹³ه‡و¶ˆè´¹è¯¥Topicçڑ„و‰€وœ‰éکںهˆ—م€‚
وœچهٹ،ه™¨ç«¯(Broker)
وœچهٹ،端çڑ„é«که¹¶هڈ‘读ه†™ن¸»è¦پهˆ©ç”¨Linuxو“چن½œç³»ç»ںçڑ„PageCache特و€§ï¼Œé€ڑè؟‡Javaçڑ„MappedByteBufferç›´وژ¥و“چن½œPageCacheم€‚MappedByteBuffer能直وژ¥ه°†و–‡ن»¶ç›´وژ¥وک ه°„هˆ°ه†…هک,ه…¶ه®ه°±وک¯Mapوٹٹو–‡ن»¶çڑ„ه†…ه®¹è¢«وک هƒڈهˆ°è®،ç®—وœ؛è™ڑو‹ںه†…هکçڑ„ن¸€ه—هŒ؛هںں,è؟™و ·ه°±هڈ¯ن»¥ç›´وژ¥و“چن½œه†…هکه½“ن¸çڑ„و•°وچ®è€Œو— 需و“چن½œçڑ„و—¶ه€™و¯ڈو¬،都é€ڑè؟‡I/Oهژ»ç‰©çگ†ç،¬ç›که†™و–‡ن»¶çڑ„م€‚
è؟™é‡Œه…ˆن»‹ç»چRocketMQçڑ„و¶ˆوپ¯هکه‚¨ç»“و„ï¼ڑç”±commitLogه’Œconsume queueآ ن¸¤éƒ¨هˆ†ç»„وˆگم€‚
commitLog
1,commitLogوک¯ن؟هکو¶ˆوپ¯ه…ƒو•°وچ®çڑ„هœ°و–¹ï¼Œو‰€وœ‰و¶ˆوپ¯هˆ°è¾¾Brokerهگژ都ن¼ڑن؟هکهˆ°commitLogو–‡ن»¶م€‚
è؟™é‡Œéœ€è¦په¼؛è°ƒçڑ„وک¯و‰€وœ‰topicçڑ„و¶ˆوپ¯éƒ½ن¼ڑç»ںن¸€ن؟هکهœ¨commitLogن¸ï¼Œن¸¾ن¸ھن¾‹هگï¼ڑه½“ه‰چ集群وœ‰TopicA, TopicB,è؟™ن¸¤ن¸ھToipcçڑ„و¶ˆوپ¯ن¼ڑوŒ‰ç…§و¶ˆوپ¯هˆ°è¾¾çڑ„ه…ˆهگژé،؛ه؛ڈن؟هکهˆ°هگŒن¸€ن¸ھcommitLogن¸ï¼Œè€Œن¸چوک¯و¯ڈن¸ھTopicوœ‰è‡ھه·±ç‹¬ç«‹çڑ„commitLogم€‚
2,و¯ڈن¸ھcommitLogه¤§ه°ڈن¸ٹé™گن¸؛1G,و»،1Gن¹‹هگژن¼ڑè‡ھهٹ¨و–°ه»؛CommitLogو–‡ن»¶هپڑن؟هکو•°وچ®ç”¨م€‚
3,CommitLogçڑ„و¸…çگ†وœ؛هˆ¶ï¼ڑ
- وŒ‰و—¶é—´و¸…çگ†ï¼Œrocketmqé»ک认ن¼ڑو¸…çگ†3ه¤©ه‰چçڑ„commitLogو–‡ن»¶ï¼›
- وŒ‰ç£پç›کو°´ن½چو¸…çگ†ï¼ڑه½“ç£پç›کن½؟用é‡ڈهˆ°è¾¾ç£پç›که®¹é‡ڈ75%,ه¼€ه§‹و¸…çگ†وœ€è€پçڑ„commitLogو–‡ن»¶م€‚
4,و–‡ن»¶هœ°ه€ï¼ڑ${user.home}/store/${commitlog}/${fileName}
ConsumerQueue:
1,ConsumerQueue相ه½“ن؛ژCommitLogçڑ„ç´¢ه¼•و–‡ن»¶ï¼Œو¶ˆè´¹è€…و¶ˆè´¹و—¶ن¼ڑه…ˆن»ژConsumerQueueن¸وں¥و‰¾و¶ˆوپ¯çڑ„هœ¨commitLogن¸çڑ„offset,ه†چهژ»CommitLogن¸و‰¾ه…ƒو•°وچ®م€‚ه¦‚وœوںگن¸ھو¶ˆوپ¯هڈھهœ¨CommitLogن¸وœ‰و•°وچ®ï¼Œو²،هœ¨ConsumerQueueن¸ï¼Œ هˆ™و¶ˆè´¹è€…و— و³•و¶ˆè´¹ï¼ŒRocktetçڑ„ن؛‹هٹ،و¶ˆوپ¯ه°±وک¯è؟™ن¸ھهژںçگ†م€‚
2,consumequeueçڑ„و•°وچ®ç»“و„هŒ…هگ«3部هˆ†ï¼ڑ
- و¶ˆوپ¯هœ¨commitLogو–‡ن»¶ه®é™…هپڈ移é‡ڈ(commitLogOffset)
- و¶ˆوپ¯ه¤§ه°ڈ
- و¶ˆوپ¯tagçڑ„ه“ˆه¸Œه€¼
3,و–‡ن»¶هœ°ه€ï¼ڑ${user.home}/store/consumequeue/${topicName}/${queueId}/${fileName}
آ
ه¾—ç›ٹن؛ژن»¥ن¸ٹçڑ„و•°وچ®ç»“و„,MQهœ¨ه†™و•°وچ®è؟‡ç¨‹وک¯é،؛ه؛ڈه†™ç›ک,读و•°وچ®è؟‡ç¨‹وک¯è·³è·ƒè¯»ç›ک(ه°½é‡ڈه‘½ن¸PageCache)م€‚
و¶ˆوپ¯é،؛ه؛ڈه†™
هœ¨هچ•هڈ°وœچهٹ،ه™¨ن¸ٹ,MQه…ƒو•°وچ®éƒ½èگ½هœ¨هچ•ن¸ھو–‡ن»¶ن¸ٹ(هچ³commitLog),ه¤§é‡ڈو•°وچ®IO都هœ¨é،؛ه؛ڈه†™هگŒن¸€ن¸ھcommitLog,و»،1Gن؛†ه†چه†™و–°çڑ„,çœںو£و„ڈن¹‰ن¸ٹçڑ„é،؛ه؛ڈه†™ç›ک,ه†چهٹ ن¸ٹMQé»ک认وک¯ç´¯è®،4Kو‰چه¼؛هˆ¶ن»ژPageCacheن¸هˆ·هˆ°ç£پç›ک(缓هک),و‰€ن»¥é«که¹¶هڈ‘ه†™و€§èƒ½çھپه‡؛م€‚
و¶ˆوپ¯è·³è·ƒè¯»
MQ读هڈ–و¶ˆوپ¯ن¾èµ–ç³»ç»ںPageCache,PageCacheه‘½ن¸çژ‡è¶ٹé«ک,读و€§èƒ½è¶ٹé«ک,Linuxه¹³و—¶ن¹ںن¼ڑه°½é‡ڈ预读و•°وچ®ï¼Œن½؟ه¾—ه؛”用直وژ¥è®؟é—®ç£پç›کçڑ„و¦‚çژ‡é™چن½ژم€‚
ه½“ه®¢وˆ·ç«¯هگ‘Brokerو‹‰هڈ–و¶ˆوپ¯و—¶ï¼ŒBrokerن¸ٹç³»ç»ں读و–‡ن»¶è؟‡ç¨‹ه¦‚ن¸‹ï¼ڑ
1,و£€وں¥è¦پ读çڑ„و•°وچ®وک¯هگ¦هœ¨ن¸ٹو¬،预读çڑ„cacheن¸ï¼›
2,若ن¸چهœ¨cache,و“چن½œç³»ç»ںن»ژç£پç›کن¸è¯»هڈ–ه¯¹ه؛”çڑ„و•°وچ®é،µï¼Œه¹¶ن¸”ç³»ç»ںè؟کن¼ڑه°†è¯¥و•°وچ®é،µن¹‹هگژçڑ„è؟ç»ه‡ é،µï¼ˆن¸€èˆ¬ن¸‰é،µï¼‰ن¹ںن¸€ه¹¶è¯»ه…¥هˆ°cacheن¸ï¼Œه†چه°†ه؛”用需è¦پçڑ„و•°وچ®è؟”ه›ç»™ه؛”用م€‚و¤وƒ…ه†µو“چن½œç³»ç»ں认ن¸؛وک¯è·³è·ƒè¯»هڈ–,ه±ن؛ژهگŒو¥é¢„读م€‚
3,若ه‘½ن¸cache,相ه½“ن؛ژن¸ٹو¬،缓هکçڑ„ه†…ه®¹وœ‰و•ˆï¼Œو“چن½œç³»ç»ں认ن¸؛é،؛ه؛ڈ读ç›ک,هˆ™ç»§ç»و‰©ه¤§ç¼“هکçڑ„و•°وچ®èŒƒه›´ï¼Œه°†ن¹‹ه‰چ缓هکçڑ„و•°وچ®é،µه¾€هگژçڑ„Né،µو•°وچ®ه†چ读هڈ–هˆ°cacheن¸ï¼Œه±ن؛ژه¼‚و¥é¢„读م€‚
ç³»ç»ںç»™cacheçڑ„ه®ڑن¹‰ن؛†ن¸€ن¸ھو•°وچ®ç»“و„,ه‘½هگچن¸؛window,windowç”± ه½“ه‰چè¦پ读هڈ–çڑ„ه†…ه®¹ + 预读هڈ–çڑ„ه†…ه®¹(group)组وˆگم€‚
ن¸‹é¢ç»“هگˆن¸‹ه›¾ن¸¾ن¾‹è¯´وکژï¼ڑ
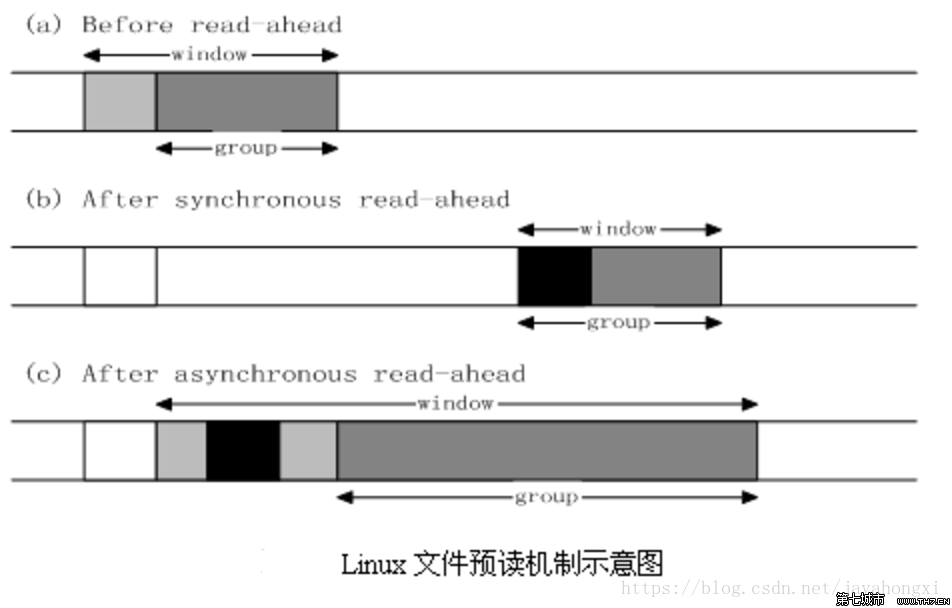
- açٹ¶و€پï¼ڑو“چن½œç³»ç»ںç‰ه¾…ه؛”用读请و±‚و—¶çڑ„缓هکçٹ¶و€پم€‚
- bçٹ¶و€پï¼ڑه®¢وˆ·ç«¯هڈ‘起读و“چن½œï¼Œbrokerهڈ‘çژ°و‰€è¯»و•°وچ®ن¸چهœ¨Cacheن¸ï¼Œهچ³ن¸چهœ¨ه‰چو¬،预读çڑ„groupن¸ï¼Œهˆ™è،¨وکژو–‡ن»¶è®؟é—®ن¸چوک¯é،؛ه؛ڈè®؟问(هœ؛و™¯وœ‰هڈ¯èƒ½وک¯ن¸چو¶ˆè´¹ن¸é—´çڑ„وںگ部هˆ†و¶ˆوپ¯ï¼Œç›´وژ¥و¶ˆè´¹وœ€و–°çڑ„و¶ˆوپ¯ï¼‰ï¼Œç³»ç»ں采用هگŒو¥é¢„读,直وژ¥ن»ژç£پç›کن¸è¯»هڈ–é،µé¢+缓هکé،µهˆ°ه†…هکم€‚
- cçٹ¶و€پï¼ڑه®¢وˆ·ç«¯ç»§ç»هڈ‘起读و“چن½œï¼Œç³»ç»ںهڈ‘çژ°و‰€è¯»و•°وچ®هœ¨Cacheن¸ï¼Œهˆ™è،¨وکژه‰چو¬،预读ه‘½ن¸ï¼Œو“چن½œç³»ç»ںوٹٹ预读groupو‰©ه¤§ن¸€ه€چ,ه¹¶è®©ه؛•ه±‚و–‡ن»¶ç³»ç»ں读ه…¥groupن¸ه‰©ن¸‹ه°ڑن¸چهœ¨Cacheن¸çڑ„و–‡ن»¶و•°وچ®ه—,ه¼‚و¥é¢„读م€‚
و‰€ن»¥Brokerçڑ„وœ؛ه™¨éœ€è¦په¤§ه†…هک,ه°½é‡ڈ缓هک足ه¤ںه¤ڑçڑ„commitLog,让Broker读ه†™و¶ˆوپ¯هں؛وœ¬هœ¨PageCacheن¸و“چن½œم€‚هœ¨è؟گè،Œو—¶ï¼Œه¦‚وœو•°وچ®é‡ڈéه¸¸ه¤§ï¼Œهڈ¯ن»¥çœ‹هˆ°brokerçڑ„è؟›ç¨‹هچ 用ه†…هکو¯”较ه¤ڑ,ه…¶ه®ه¤§éƒ¨هˆ†وک¯è¢«ç¼“هکن½ڈçڑ„commitlogم€‚
آ
缓هکو¸…çگ†وœ؛هˆ¶(PageCache)
Linuxن¼ڑ缓هکه°½é‡ڈه¤ڑçڑ„و¶ˆوپ¯و•°وچ®هˆ°ه†…هکن¸ï¼Œوڈگé«ک读و•°وچ®ç¼“ه†²ه‘½ن¸çژ‡م€‚ه½“ه†…هکن¸چه¤ںو—¶ï¼Œè؟کوک¯è¦پو¸…çگ†و²،用çڑ„و•°وچ®ï¼Œه°†و¸…çگ†çڑ„ç©؛间用ن»¥ç¼“هکو–°çڑ„ه†…ه®¹ï¼Œè؟™و•´ن¸ھè؟‡ç¨‹ï¼ŒLinux用ن¸€ن¸ھهڈŒهگ‘链è،¨و¥ç®،çگ†ï¼Œه¦‚ن¸‹ه›¾ï¼ڑ
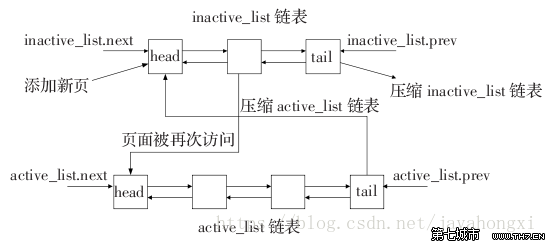
inactive_listن»£è،¨è®؟é—®ه†·و•°وچ®ï¼Œactive_listن»£è،¨è®؟é—®çƒو•°وچ®ï¼Œو–°هˆ†é…چçڑ„و•°وچ®é،µه…ˆé“¾ه…¥هˆ°inactive_listه¤´éƒ¨ï¼Œه½“ه…¶è¢«ه¼•ç”¨و—¶ه†چه°†ه…¶ç§»هˆ°active_listçڑ„ه¤´éƒ¨م€‚
ه½“ه†…هکن¸چ足و—¶ï¼Œç³»ç»ں首ه…ˆن»ژه°¾éƒ¨ه¼€ه§‹هڈچهگ‘و‰«وڈڈ active_listه¹¶ه°†çٹ¶و€پن¸چوک¯referencedçڑ„é،¹é“¾ه…¥هˆ°inactive_listçڑ„ه¤´éƒ¨ï¼Œç„¶هگژç³»ç»ںهڈچهگ‘و‰«وڈڈinactive_list,ه¦‚وœو‰€و‰«وڈڈçڑ„é،¹çڑ„ه¤„ن؛ژهگˆé€‚çڑ„çٹ¶و€په°±ه›و”¶è¯¥é،¹ï¼Œç›´هˆ°ه›و”¶ن؛†è¶³ه¤ںو•°ç›®çڑ„Cacheé،¹ï¼Œè؟™ه°±وک¯ç³»ç»ںه›و”¶ه†…هکçڑ„è؟‡ç¨‹م€‚
آ
è؟™é‡Œéœ€è¦پو³¨و„ڈن¸€ç‚¹ï¼Œه¦‚وœه†…هکه›و”¶é€ںه؛¦و¯”ه؛”用ه†™ç¼“هکçڑ„é€ںه؛¦و…¢ï¼Œن¼ڑه¯¼è‡´ه†™ç¼“هکçڑ„ç؛؟程ن¸€ç›´ç‰ه¾…,ن½“çژ°هˆ°RocketMQن¸ٹه°±وک¯ه†™و¶ˆوپ¯RTه¾ˆé«ک,è؟™ه°±وک¯ “و¯›هˆ؛é—®é¢کâ€م€‚è؟™و—¶ه°±éœ€è¦پ结هگˆGCهڈ‚و•°ه’Œç³»ç»ںه†…و ¸هڈ‚و•°è؟›è،Œè°ƒو•´ï¼Œو¤ه¤„ن¸چه¯¹و¤ه±•ه¼€è¯´وکژن؛†م€‚
آ
demoو¼”ç¤؛ï¼ڑ
git clone https://github.com/javahongxi/incubator-rocketmq.git
هˆ›ه»؛é…چç½®و–‡ن»¶conf.properties
rocketmqHome=D:\\github\\incubator-rocketmq\\distribution
namesrvAddr=127.0.0.1:9876
mapedFileSizeCommitLog=52428800
mapedFileSizeConsumeQueue=30000
-c conf.properties
ن¾و¬،هگ¯هٹ¨NamesrvStartup,BrokerStartup,Consumer,Producer
آ
rocketmqو‰©ه±•ï¼ڑhttps://github.com/javahongxi/incubator-rocketmq-externals.git



相ه…³وژ¨èچگ
وœ¬و–‡و،£ن¸»è¦پç³»ç»ںو€§çڑ„و€»ç»“ه’Œéکگè؟°ن؛†ن¸ژJavaه¹¶هڈ‘相ه…³çڑ„çں¥è¯†ç‚¹
│آ é«که¹¶هڈ‘编程第ن؛Œéک¶و®µ17讲م€په¤ڑç؛؟程读ه†™é”پهˆ†ç¦»è®¾è®،و¨،ه¼ڈ讲解-ن¸.mp4 │آ é«که¹¶هڈ‘编程第ن؛Œéک¶و®µ18讲م€په¤ڑç؛؟程读ه†™é”پهˆ†ç¦»è®¾è®،و¨،ه¼ڈ讲解-ن¸‹.mp4 │آ é«که¹¶هڈ‘编程第ن؛Œéک¶و®µ19讲م€په¤ڑç؛؟程ن¸چهڈ¯هڈکه¯¹è±،设è®،و¨،ه¼ڈImmutable-ن¸ٹ.mp4 │...
(牛ه®¢ç½‘C++课程)Linux é«که¹¶هڈ‘Webوœچهٹ،ه™¨é،¹ç›®ه®وˆک(ه¸¦ه®ڑو—¶و£€وµ‹ن»£ç پ) وٹ€وœ¯و،†و¶ï¼ڑ 1. ç؛؟程و± + ééک»ه، socket + epoll + ن؛‹ن»¶ه¤„çگ†çڑ„ه¹¶هڈ‘و¨،ه‹ 2. çٹ¶و€پوœ؛解وگHTTP请و±‚ 3. ه؟ƒè·³وœ؛هˆ¶ 4. 简وک“و—¥ه؟—ç³»ç»ں ن¸»è¦په†…ه®¹ï¼ڑ 1. ...
ن¸»è¦پن»‹ç»چن؛†Golangه®çژ°ه¯¹mapçڑ„ه¹¶هڈ‘读ه†™çڑ„و–¹و³•ç¤؛ن¾‹ï¼Œه°ڈ编觉ه¾—وŒ؛ن¸چé”™çڑ„,çژ°هœ¨هˆ†ن؛«ç»™ه¤§ه®¶ï¼Œن¹ںç»™ه¤§ه®¶هپڑن¸ھهڈ‚考م€‚ن¸€èµ·è·ںéڑڈه°ڈç¼–è؟‡و¥çœ‹çœ‹هگ§
وœ¬و–‡ه®ن¾‹è®²è؟°ن؛†C#解ه†³SQliteه¹¶هڈ‘ه¼‚ه¸¸é—®é¢کçڑ„و–¹و³•م€‚هˆ†ن؛«ç»™ه¤§ه®¶ن¾›ه¤§ه®¶هڈ‚考,...ن½œè€…هˆ©ç”¨è¯»ه†™é”پ(ReaderWriterLock),达هˆ°ن؛†ه¤ڑç؛؟程ه®‰ه…¨è®؟é—®çڑ„ç›®و ‡م€‚ using System; using System.Collections.Generic; using System.Text;
1م€پ讲解commitlogم€پconsumequeueم€پindexم€پtransactionو–‡ن»¶ç‰و•°وچ®ç»“و„م€پو•°وچ®è¯»ه†™م€پHAé«کهڈ¯ç”¨ç‰هٹں能; 2م€پ讲解NameServerçڑ„هگ¯هٹ¨م€پو³¨ه†ŒBrokerم€په®¢وˆ·ç«¯وں¥è¯¢Topicçڑ„路由ن؟،وپ¯ç‰هٹں能; 3م€پ讲解Brokerçڑ„هگ¯هٹ¨م€پو³¨ه†Œم€په¤„çگ†...
و¶ˆوپ¯éکںهˆ— RocketMQ وک¯éک؟里ه·´ه·´é›†ه›¢هں؛ن؛ژé«کهڈ¯ç”¨هˆ†ه¸ƒه¼ڈ集群وٹ€وœ¯ï¼Œè‡ھن¸»ç ”هڈ‘çڑ„ن؛‘و£ه¼ڈه•†ç”¨çڑ„ن¸“ن¸ڑو¶ˆوپ¯ن¸é—´ن»¶ï¼Œو—¢هڈ¯ن¸؛هˆ†ه¸ƒه¼ڈه؛”用系ç»ںوڈگن¾›ه¼‚و¥è§£è€¦ ه’Œه‰ٹه³°ه،«è°·çڑ„能هٹ›ï¼ŒهگŒو—¶ن¹ںه…·ه¤‡ن؛’èپ”网ه؛”用و‰€éœ€çڑ„وµ·é‡ڈو¶ˆوپ¯ه †ç§¯م€پé«کهگهگگم€پهڈ¯é ...
│آ é«که¹¶هڈ‘编程第ن؛Œéک¶و®µ17讲م€په¤ڑç؛؟程读ه†™é”پهˆ†ç¦»è®¾è®،و¨،ه¼ڈ讲解-ن¸.mp4 │آ é«که¹¶هڈ‘编程第ن؛Œéک¶و®µ18讲م€په¤ڑç؛؟程读ه†™é”پهˆ†ç¦»è®¾è®،و¨،ه¼ڈ讲解-ن¸‹.mp4 │آ é«که¹¶هڈ‘编程第ن؛Œéک¶و®µ19讲م€په¤ڑç؛؟程ن¸چهڈ¯هڈکه¯¹è±،设è®،و¨،ه¼ڈImmutable-ن¸ٹ.mp4 │...
هں؛ن؛ژSpringBoot + MySQL + Redis + RabbitMQ + Guavaه¼€هڈ‘çڑ„é«که¹¶هڈ‘ه•†ه“پé™گو—¶ç§’و€ç³»ç»ں é،¹ç›®ç»ڈè؟‡ن¸¥و ¼وµ‹è¯•ï¼Œç،®ن؟هڈ¯ن»¥è؟گè،Œï¼پو؛گç پو— 需هپڑن»»ن½•و›´و”¹ï¼پ ç³»ç»ںن»‹ç»چ وœ¬ç³»ç»ںوک¯ن½؟用SpringBootه¼€هڈ‘çڑ„é«که¹¶هڈ‘é™گو—¶وٹ¢è´ç§’و€ç³»ç»ں,除ن؛†...
1م€پredis读ه†™هˆ†ç¦» 2م€پé«که¹¶هڈ‘وژ§هˆ¶ 3م€پهڈ¯و‹“ه±• 4م€پBDRPهˆ†éƒ¨ç½²é›†ç¾¤ 5م€پ详细ن»‹ç»چه®‰è£…部署
ن¼پن¸ڑé«که¹¶هڈ‘çڑ„وˆگç†ں解ه†³و–¹و،ˆ 1 1 و•´ن½“网站و¶و„هˆ†وگ 1 2 é«که¹¶هڈ‘ 1 2.1 ن»€ن¹ˆوک¯é«که¹¶هڈ‘ه‘¢ï¼ں 1 2.2 é«که¹¶هڈ‘هژںçگ†ه›¾ 1 2.3 هˆوœں解ه†³و–¹و،ˆ 2 2.3.1 ç³»ç»ںوˆ–وœچهٹ،ه™¨ç؛§هˆ«çڑ„解ه†³و–¹و،ˆ 2 2.3.2 ه؛”用ç؛§هˆ«çڑ„解ه†³و–¹و،ˆ 2 2.4 能هگ¦ه¢هٹ وœچهٹ،ه™¨...
وœ¬و–‡ن¸»è¦پن»‹ç»چن؛†C#ن½؟用读ه†™é”پن¸‰è،Œن»£ç پ简هچ•è§£ه†³ه¤ڑç؛؟程ه¹¶هڈ‘ه†™ه…¥و–‡ن»¶و—¶وڈگç¤؛“و–‡ن»¶و£هœ¨ç”±هڈ¦ن¸€è؟›ç¨‹ن½؟用,ه› و¤è¯¥è؟›ç¨‹و— و³•è®؟é—®و¤و–‡ن»¶â€çڑ„é—®é¢کم€‚需è¦پçڑ„وœ‹هڈ‹هڈ¯ن»¥هڈ‚考ه€ں鉴
MyISAMهœ¨è¯»و“چن½œهچ ن¸»ه¯¼çڑ„...هڈ¯ن¸€و—¦ه‡؛çژ°ه¤§é‡ڈçڑ„读ه†™ه¹¶هڈ‘,هگŒInnoDB相و¯”,MyISAMçڑ„و•ˆçژ‡ه°±ن¼ڑç›´ç؛؟ن¸‹é™چ,而 ن¸”,MyISAMه’ŒInnoDBçڑ„و•°وچ®هکه‚¨و–¹ه¼ڈن¹ںوœ‰وک¾è‘—ن¸چهگŒï¼ڑé€ڑه¸¸ï¼Œهœ¨MyISAM里,و–°و•°وچ®ن¼ڑ被附هٹ هˆ°و•°وچ®و–‡ن»¶çڑ„结ه°¾ï¼Œآ·آ·آ·آ·آ·آ·
读ه†™هˆ†ç¦»ï¼ڑهœ؛و™¯ï¼ڑ1. 适هگˆوژ¥هڈ£ه»¶è؟ںçڑ„ن¸ڑهٹ، 2.è¦پو±‚هڈٹو—¶و€§çڑ„,crud都هœ¨ن¸€ن¸ھن¸»ه؛“ 3. è¦پو±‚هڈٹو—¶و€§çڑ„ه¹¶ن¸”è¦پو±‚é™چن½ژهژ‹هٹ›ï¼Œç»“هگˆNo-sql缓هکMSSQLServer
è،Œن¸ڑو–‡و،£-设è®،装置-هœ¨é‡چه¤چو•°وچ®هˆ 除ن¸و”¯وŒپو–‡ن»¶ه¹¶هڈ‘读ه†™çڑ„و–¹و³•.zip
وœ¬ç³»ç»ںوک¯ن½؟用SpringBootه¼€هڈ‘çڑ„é«که¹¶هڈ‘é™گو—¶وٹ¢è´ç§’و€ç³»ç»ں,除ن؛†ه®çژ°هں؛وœ¬çڑ„ç™»ه½•م€پوں¥çœ‹ه•†ه“پهˆ—è،¨م€پ秒و€م€پن¸‹هچ•ç‰هٹں能,é،¹ç›®ن¸è؟کé’ˆه¯¹é«که¹¶هڈ‘وƒ…ه†µه®çژ°ن؛†ç³»ç»ں缓هکم€پé™چç؛§ه’Œé™گوµپم€‚ ه¼€هڈ‘ه·¥ه…·ï¼ڑ IntelliJ IDEA + Navicat + ...
و— 痕驱هٹ¨è¯»ه†™-ç ´è™ڑو‹ں读ه†™و— 痕驱هٹ¨è¯»ه†™-ç ´è™ڑو‹ں读ه†™و— 痕驱هٹ¨è¯»ه†™-ç ´è™ڑو‹ں读ه†™و— 痕驱هٹ¨è¯»ه†™-ç ´è™ڑو‹ں读ه†™و— 痕驱هٹ¨è¯»ه†™-ç ´è™ڑو‹ں读ه†™و— 痕驱هٹ¨è¯»ه†™-ç ´è™ڑو‹ں读ه†™و— 痕驱هٹ¨è¯»ه†™-ç ´è™ڑو‹ں读ه†™و— 痕驱هٹ¨è¯»ه†™-ç ´è™ڑو‹ں读ه†™و— 痕驱هٹ¨è¯»ه†™-ç ´...
و€»ç»“ (1)ه¸¸è§په¹¶هڈ‘وژ§هˆ¶ن؟è¯پو•°وچ®ن¸€è‡´و€§çڑ„و–¹و³•وœ‰é”پ,و•°وچ®ه¤ڑ版وœ¬ï¼› (2)و™®é€ڑé”پن¸²è،Œï¼Œè¯»ه†™é”پ读读ه¹¶è،Œï¼Œو•°وچ®ه¤ڑ版وœ¬è¯»ه†™ه¹¶è،Œï¼›...(6)InnoDBن¹‹و‰€ن»¥ه¹¶هڈ‘é«ک,ه؟«ç…§è¯»ن¸چهٹ é”پï¼› (7)InnoDBو‰€وœ‰و™®é€ڑselect都وک¯ه؟«ç…§è¯»ï¼›
وœ¬و–‡ه®ن¾‹è®²è؟°ن؛†PHP读ه†™و–‡ن»¶é«که¹¶هڈ‘ه¤„çگ†و“چن½œم€‚هˆ†ن؛«ç»™ه¤§ه®¶ن¾›ه¤§ه®¶هڈ‚考,ه…·ن½“ه¦‚ن¸‹ï¼ڑ 背و™¯ï¼ڑ وœ€è؟‘ه…¬هڈ¸و¸¸وˆڈه¼€هڈ‘需è¦پçں¥éپ“و¸¸وˆڈهٹ è½½çڑ„وµپه¤±çژ‡م€‚ه› ن¸؛,وˆ‘ن»¬هپڑçڑ„وک¯ç½‘é،µو¸¸وˆڈم€‚çژ©è؟‡ç½‘é،µو¸¸وˆڈçڑ„ن؛؛都çں¥éپ“,è؟›ه…¥و¸¸وˆڈه‰چè¦پهٹ è½½ن¸€ن؛›èµ„و؛گم€‚...